In this blog, we will be implementing linear regression in two ways. The first is an exact, analytical implementation of least-sqaures linear regression and the second is a gradient descent implementation.
The loss function for this empirical risk minimization problem is defined as follows.
$L() = || ||^2_2 $
To start, we want to take the gradient of \(L(\textbf{w})\) with respect to \(\textbf{\hat{w}}\).
$ L() = 2$
From here, we will implement both of our fit methods, test them, and then perform some experiements using the linear regression model.
Demo
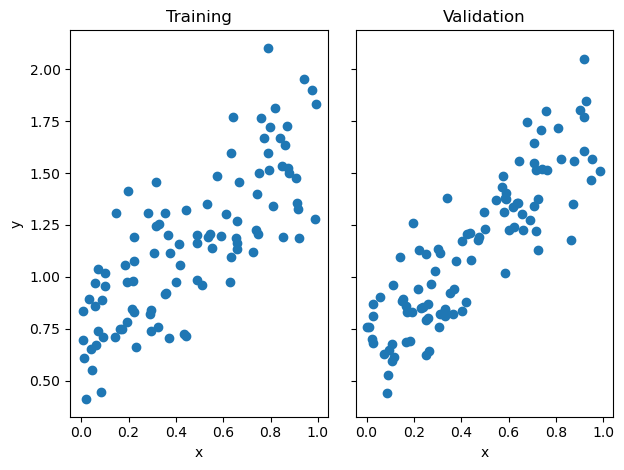
Generate and Plot Data
This initial example is p=1 for visualization purposes. Later in this post we will experiment with p values of different sizes.
Let’s use this data to test both our analytical and gradient fit methods. We will show that both of our fit methods result in the same values for the prediction vertor \(\mathbf{w}\). The score on the training data and the validation data is calculated using the coefficient of determination, referred to as \(c\).
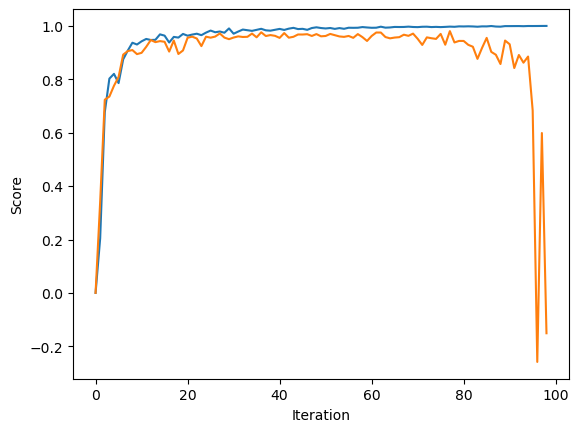
The first experiment we are going to perform is allowing p_features, the number of features, to increase while the number of training points, n_train, remains the same.
Here we see both scores increasing at first but the score val beginning to fluctuate pretty widely once we get past around 65 features while the training score continues to approach and possibly reach 1. This is because the training model is able to refit directly based on the number of features and as the features increase, as does the liklihood overfitting. It appears that we reach a certain point where increasing the number of features no longer increases the accuracy because the model becomes to overfit to accurately make predictions on the test data. That is why we see the score_val starting to drop, slowly at first and then drastically.
Lasso Regularization
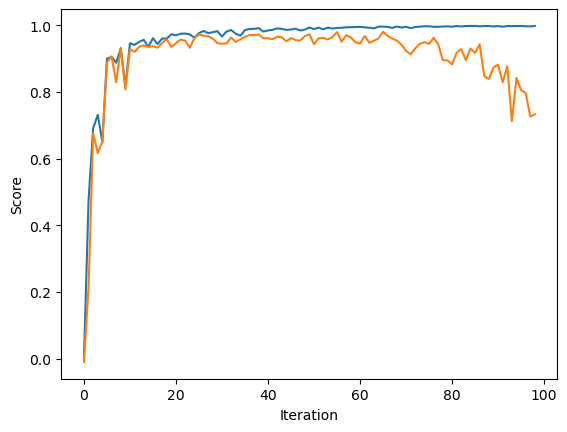
Next, we will implement Lasso Regularization using the SciKit Learn implementation.
There are somewhat similar results in this LASSO experiment as we saw for Linear Regression however the variation of the validation score is much smaller. So overall the validation score seems to be higher with LASSO than linear regression. Also similarly to above, it appears that the reason that the validation score drops while training score continues to increase is that our model is overfitting on the training data. The result of this is an extremely high training accuracy (very close to or at 1) and a dropping testing accuracy. This LASSO experiment seems to prevent some of the extreme overfitting we saw above that led to the validation score fluctuating wildly, but the model is still overfitting as the accuracy clearly decreases past a certain number of iterations.